TF-IDF ( Term Frequency-Inverse Document Frequency )
LLM의 등장으로 텍스트 관련 클래시컬한 알고리즘은 많이 쓰이지 않는 추세이지만 여전히 Data Science 나 대용량의 text 데이터를 처리 할 때, 혹은 검색 엔진과 추천시스템 등에도 해당 TF-IDF는 여전
aiden0729.tistory.com
위의 글에서 TF-IDF에 대해서 언급한 적이 있는데, 이번에 말해볼 bm25는 TF-IDF의 진화 형태정도 되는 격이라고 할 수 있겠다.
재밌는건 bm25는 Best Matching 25 의 줄임말인데, 25는 해당 알고리즘을 개발하던 Okapi 그룹에서 25번 째 테스트에서 가장 좋은 결과가 나와서 이름이 붙었다고 한다. IT랑 다소 거리가 있는 패션/니치시장인 향수나 위스키 (샤넬 넘버 5, 메이커스마크 46 ) 처럼 네이밍이 되어있는 꽤 낭만있는(?) 명명법이다.
TF-IDF는 훌륭한 방법이지만 사실 '정규화'가 되어있지 않다. 정규화란 '횟수'와 '문서길이' 모두에 대한 정규화를 의미한다. 예를들어 총 문서가 100개인데 'apple'이라는 단어가 아래와 같이 나왔다고 가정해보자 ( 나머지 98개 문서에는 apple이라는 단어는 없다고 가정한다 )
| 문서 | 길이 (단어 수) | apple 등장 횟수 |
| A | 10,000 | 20 |
| B | 100 | 3 |
1) TF-IDF
TF-IDF가 해당 점수를 계산한다면, 아래와 같은 방식으로 약 6.6배정도 apple에 대해 A 문서가 중요하다고 판단할 것이다.

2) bm25
일단 TF는 위에 처럼 숫자와 거의 비례한 ( log가 있지만 ) 방식으로 계산되지 않고, TF에 포화함수를 적용하여 숫자가 늘어날수록 증가폭을 작게 만들어준다. 따라서 TF가 많이 나오더라도 서서히 작아지는 경향을 띈다.
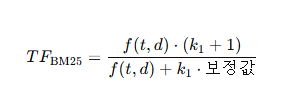
IDF는 너무 binary하게 가는 경우를 제한한다. 너무 희귀하면 IDF가 무한대에 수렴할 수도 있고, 모든 문서에 나오면 0이 나오기 때문에 부정확한 케이스가 존재하여 너무 극단적인 값이 나온다. 해당 부분 보완하기 위해 분자, 분모에 0.5를 더하고, 마지막에 +1을 더해서 스무딩을 한다.

또한 문서길이에대한 조정계수도 분모에 포함시킨다. 전체 문서의 평균길이 대비하여 문서길이에 대한 보정도의 증감을 파악한다.

위의 과정을 포함한 bm25를 계산했을때 A문서에 대한 중요도는 3.553, B문서에 대한 중요도는 3.545 로 거의 비슷한 중요도로 도출된다.
'LLM' 카테고리의 다른 글
| OpenSearch - Hybrid Search에 대해서 (0) | 2025.05.14 |
|---|---|
| OpenSearch 란 ? - AWS의 ElasticSearch, 신흥 Vector 검색의 강자가 될 것인가 (0) | 2025.05.14 |
| aNN(Approximate Nearest Neighbor) (0) | 2025.05.12 |
| kNN이란 ? ( k-Nearest Neighbors ) (0) | 2025.05.12 |
| LlmaIndex vs Langchain 01 - 라마인덱스 (0) | 2025.05.05 |