ML은 Linear Regression이나 K-means 등의 다양하면서 기초적인 알고리즘 등이 있지만
기본적으로 가장 많은 태스크를 차지하는 '예측/분류'에서 일반적으로 쓰이는 모델은 sklearn에 XGBoost나 LigtGBM 등일 것이다.이는 대표적인 MLOps의 프레임워크인 ML-Flow와 해당 프레임워크가 임베딩 되어있는 Databricks의 제작자인 현 스탠포드 교수인 Matei Zaharia (마테이 자하리아) 가 쓰는 AutoML에도 존재한다.
그만큼 가볍고 Robust한 모델이라는 방증일 것이며, 다양한 Kaggle 메인스트림 task에서도 수년 째 좋은 성적을 거두고 있다. 이는 기존의 Bagging 기법의 한계를 Boosting 기법이 어느정도 극복했기 때문이라고 생각한다. 하지만 RandomForest는 2001년 발표 이후 아직도 다양한 데이터셋의 PoC나 과적합을 방지하기 위한 목적, 민감하지 않은 파라미터 등으로 선호되고 있는 task들도 분명 있다고 생각한다.
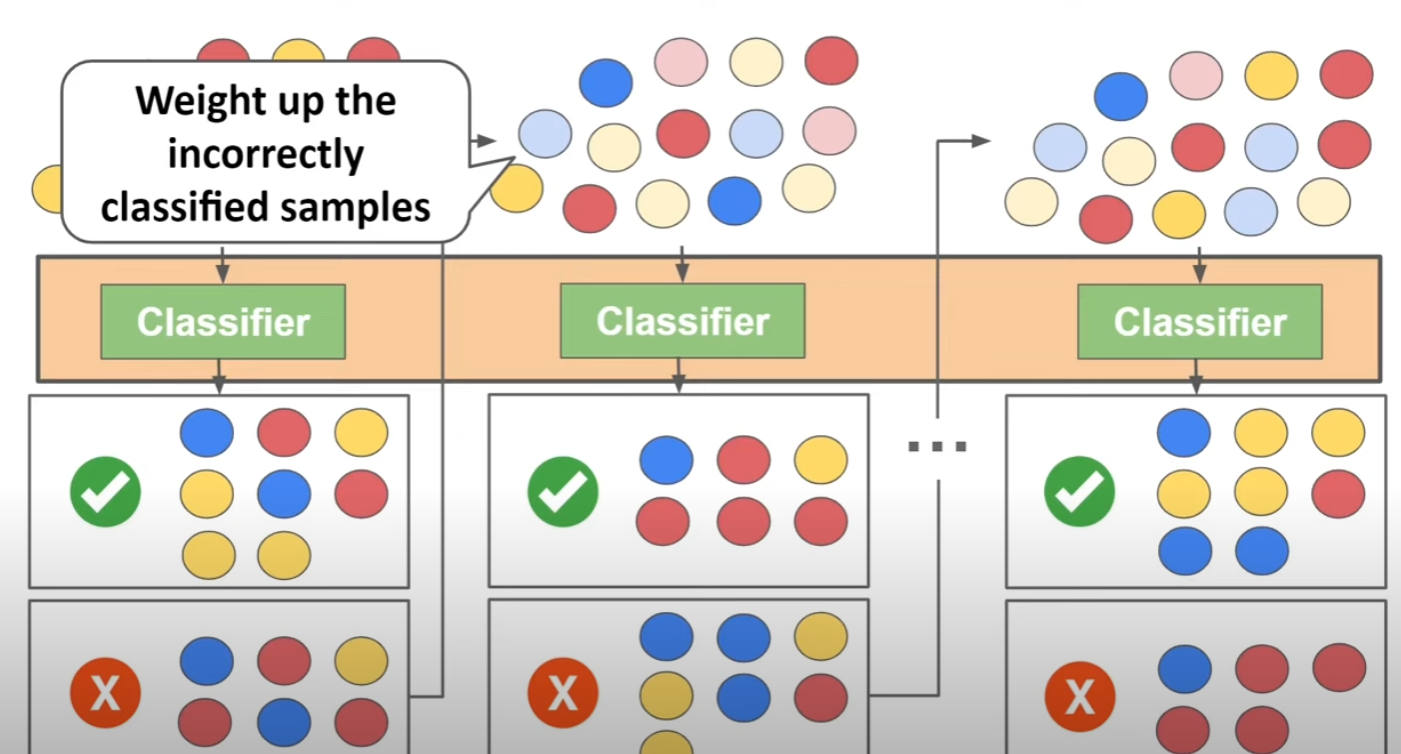
Boosting은 아래와 같이 순차적으로 작동한다.
2016년에 논문에서 발표된만큼 다소 Neural Network의 layer의 개념도 차용한 것 같다는 것이 나의 뇌피셜이다.
Tree 기반의 아주 단순한 모델들이 오차를 검증하며 다음 Tree에게 계속 더 순도 높은 정보를 넘긴다.
해당 Boosting에도 level-wise와 leaf-wise등이 있는데 결국 경량화의 개념이 탑재된 것이며, 기초적인 BFS, DFS 등의 알고리즘과 유사하기 때문에 컴퓨팅 자원, 과적합 여부 등에 대해 고려하여 선택하면 될 것 같다.
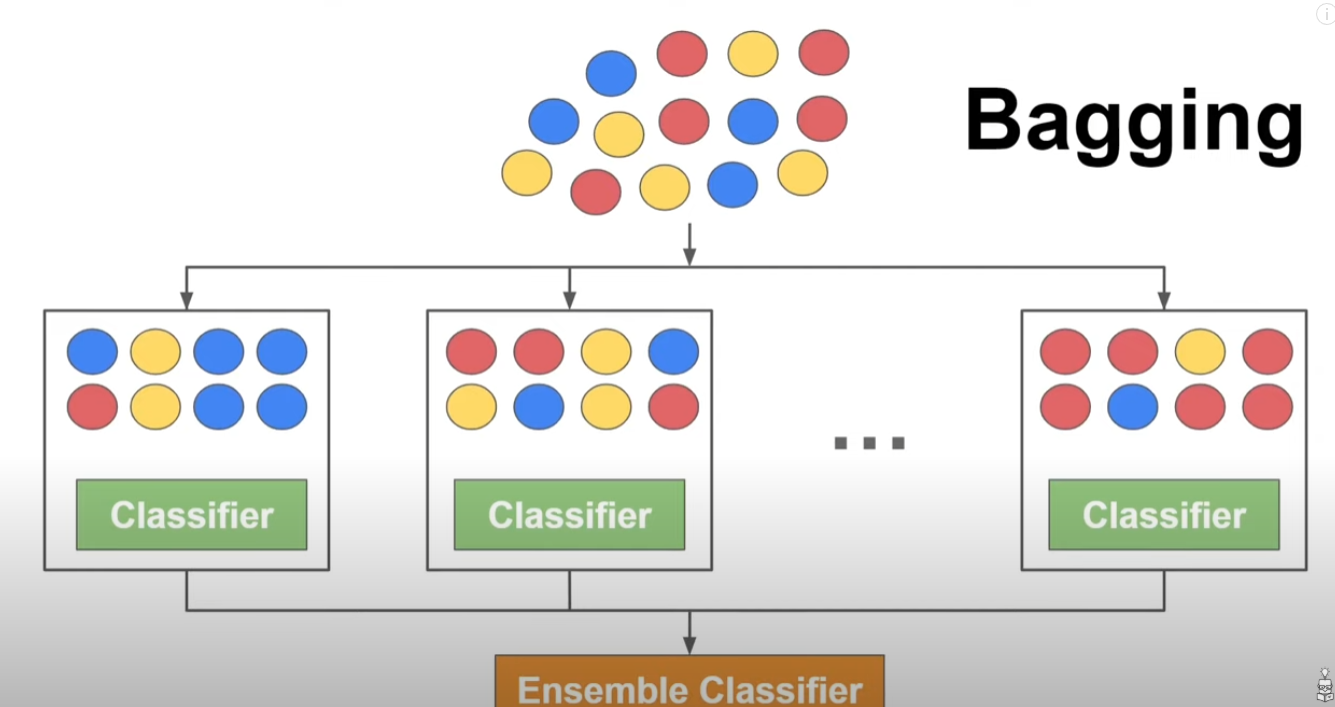
Bagging은 ML에 중요한 인물 중 한명인 Leo Breiman (UC Berkeley 통계학자)에 의해 1996년에 탄생했다.
애초에 Decision Tree 자체를 이 레오 브리먼이 1986년에 CART(Classification and Regression Tree) 라는 이름으로 설계한 내용을 발전시켰다고 보여진다.
개념 뿐만 아니라 더 appliable한 Random Forest 또한 2001년에 제시함으로써 사실상 1806년에 Gauss( 현대통계학의 피타고라스.... 제거대상....) 가 제시한 Regression의 모델을 100여년만에 복잡한 task에 대해 Appliable한 형태로 진화 발전시켰다고 할 수 있다.
그림과 같이 결국 현대 민주주의의 '투표 제도'와도 좀 닮아있다.
Boosting vs Bagging 핵심 차이
| 항목 | Boosting (예: XGBoost) | Bagging (예: Random Forest) |
| 핵심 목적 | 약한 모델을 순차적으로 보완하며 강한 모델로 만듦 | 여러 강한 모델을 병렬로 학습시켜 평균화로 안정성↑ |
| 학습 방식 | 순차적 (이전 모델의 오류를 다음 모델이 보완) | 병렬적 (모든 모델이 독립적으로 학습) |
| 모델 간 의존성 | 있음 (이전 결과를 바탕으로 다음 모델 생성) | 없음 (각 트리는 독립적) |
| 예측 방식 | 가중 평균 (weighted sum) | 단순 평균 or 투표 (majority vote or mean) |
| 과적합 대응 | 정규화, learning rate 등 추가 튜닝 필요 | 분산 감소 효과로 기본적으로 과적합에 강함 |
| 대표 알고리즘 | XGBoost, AdaBoost, LightGBM, CatBoost 등 | Random Forest, ExtraTrees 등 |
'ML & DL' 카테고리의 다른 글
| xAI와 SHAP란? - 협력 게임 이론 (0) | 2025.05.07 |
|---|---|
| 역전파(BackPropagation)란 무엇인가? (0) | 2025.05.01 |
| Deep Learning 주요 레이어 구성 (0) | 2025.05.01 |
| Classical ML vs. Deep Learning, 언제 무엇을 써야 할까? (0) | 2025.05.01 |
| Standard Scaler vs Robust Scaler (0) | 2025.04.28 |